
张奇告诉记者,对行业来说,DeepSeek在最新的文章中提到的56.3%缓存命中率(原文称,在 24 小时统计时段内,DeepSeek V3 和 R1都能实现输入 token 总数为 608B,其中 342B tokens(56.3%)命中 KVCache 硬盘缓存)是一项具有重要意义数据。
“虽然各家没有公布过相关数据,但超过一半的命中率在业内应该已是很高的水平。”张奇认为,像在DeepSeek所开发的6710亿参数超大模型上,几亿用户提问时所写的文本多多少少存在差异,在这种前提下能够实现高中率,说明团队在模型整体优化上做了很多工作。
据DeepSeek团队介绍,V3、R1推理系统的优化目标就是追求“更大的吞吐,更低的延迟。”
基于DeepSeek采取的混合专家模型核心架构(MOE),超大模型由众多规模较小的专家模型组成,并承担不同的分工。通俗用人类世界的团队合作来解释其中所需要的调度工作,如果一个团队要将各个领域的专家集合到一起来攻克某项任务,就需要事先把整体任务拆分成多个流程环节的任务,再按照分配给不同领域的专家,让他们每个人都发挥专业技能解决问题,最后汇总结论。
DeepSeek在文中写道,由于DeepSeek-V3 / R1的专家数量众多,并且按照最初的设计规则,每层256个专家在实际运行中仅激活其中8个。要实现团队的“大吞吐,低延迟”的优化目标,就需要做到短时间处理大量任务时“高效调用”每个专家,也就是DeepSeek在文中提到的“大规模跨节点专家并行(Expert Parallelism / EP)”。
“这是一项难度极大的平衡工作,如果模型优化分配上做不好,就会使得一个6000多亿参数的超大模型,每次可能只有8个或几个专家在实际运行,而且如果某一个没有运行完,剩下的所有专家可能在等待。等待则通常又意味着计算资源的浪费。”张奇认为,在DeepSeek开源前,混合专家模型的平衡设计对许多AI模型大厂都是尚未攻克的难题。
此外,据DeepSeek介绍,另外,由于白天用户访问量大、服务负荷高,晚上的服务负荷低,团队实现了一套机制,在白天负荷高的时候,利用所有模型节点部署推理服务。晚上负荷低的时候,减少推理节点,以用来做研究和训练。

一快递公司92万个涉诈包裹流向全国诈骗链条曝光一快递公司92万...
易烊千玺新片帮助公益短片推广候场时背影好落寞由易烊千玺主演的新...
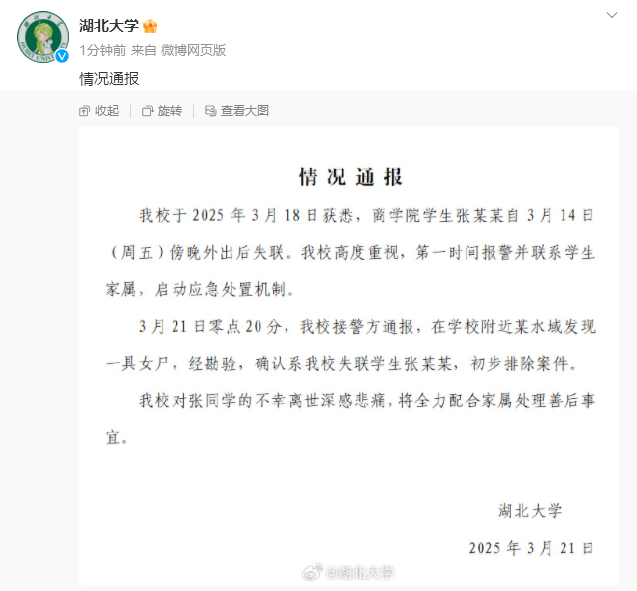
湖大失联女生遗体已找到初步排除案件3月21日,湖北大学阳逻校区...

司马南偷税被罚超900万税务部门严查违规行为国家税务总局北京市...

《管家婆新版免费内部资料,惠泽解答解释落实_iPhone版v34.v...
